When asked for estimates, you usually don’t have much more than your gut feeling to go on. You just know that this one thing is going to take longer because it’s more fragile than that other thing. But why is that?
People much smarter than me have researched this subject and there are good ways of measuring how complex a piece of code is.
Measure twice, cut once
The adage also holds true for software development: you want your code to be robust before it hits production, where malfunctioning code may incur costs. And if we’re on the wrong track, we’ll want to know as soon as possible.
There are a lot of techniques to help, like:
- unit or integration testing
- manual code review
- static analysis
Static analysis is an automated analysis of your software and there are a lot of applications: lint will catch syntax errors, CodeSniffer finds coding convention violations and Mess Detector will warn about a wide variety of rules, some of which include software metrics.
Software metrics are the computer science’s attempt to make software measurable and complexity can be measured in a few different ways.
Complex code usually means either the problem it’s solving is complicated, or that the code is of poor quality. We’re likely to see bugs in both cases. And complex code is harder to reason about, so it’ll be harder to maintain.
Cyclomatic complexity
One way of measuring complexity is by analyzing the control flow: whenever the program can take a different path depending on the input, it becomes more complex.
if ($user->isLoggedIn()) {
echo 'Welcome back, ' . $user->getName();
} else {
echo 'Hi there, stranger!';
}
In the above code example, there are 2 possible code paths: either $user is
logged in (in which case a personalized text is displayed), or isn’t (and a
generic message is shown). It has a cyclomatic complexity of 2.
The more decision paths there are, the harder it becomes to reason about the logic & test it.
Halstead intelligent content
Instead of decision paths, Halstead’s measures are based on the vocabulary of
your software: all operators (+, -, =, &&, … and all reserved words,
like if and for) and operands (values, variables & function names).
The exact formula to calculate this metric is quite complex because it tries to be programming language independent, and some languages are much more verbose than others.
But the basics are very simple: the more operators and operands, the more complex a program is:
echo 'How are you';
$array = ['how', 'are', 'you'];
$string = implode(' ', $array);
$string = ucfirst($string);
echo $string;
Both of the above snippets perform the exact same thing, but the second one is a bit more complex:
- you have to know more about the environment (what do
implode&ucfirstdo) - there are more steps to reason about
- there are more places where something could go wrong (e.g.
implodeargument order could change)
Maintainability index
A very long function can have a very low cyclomatic complexity, but still be very complex because it still does a lot of things. And if one of those is flawed, it can affect everything that follows.
Just look at these metrics for Minify. Even though in
terms of cyclomatic complexity, stripWhitespace (circled) scores low, it’s
still a pretty complex beast (just look at the code!).
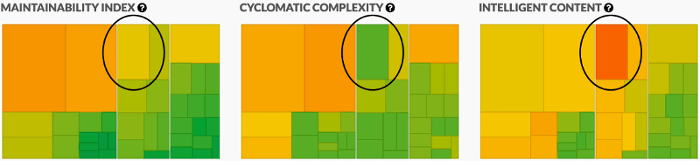
On the other hand, a function with a huge switch statement could have little
intelligent content, but a very big cyclomatic complexity.
The maintainability index is a combination of the amount of lines of code and these 2 complexity metrics in an attempt to predict how hard software is to maintain. The exact formula seems arbitrary: it was engineered to match ratings of manual analysis of software in the 80s.
A low maintainability index is a clear indicator of worrisome code. If you’re going to build something that touches that code, it’s likely going to take longer, with a much greater likelihood of bugs. Code with a high maintainability index is in dire need of refactoring.
If you’re interested in finding the complexity hotspots in your projects, head on to Cauditor, a code metrics visualization project I’ve been working on. Or run the PDepend suite if you’re only interested in the raw metrics.
Just note that complex code doesn’t necessarily mean bad code! It could also be solving a very hard problem that you might not even be able to simplify.