Cache! A-ah. Saviour of the Universe
Caching is awesome. Instead of repeating an expensive operation, just reuse the result from last time! But properly using cache can be tricky… But there are a couple of things I’d like to not have to deal with:
Caching is awesome. Instead of repeating an expensive operation, just reuse the result from last time! But properly using cache can be tricky… But there are a couple of things I’d like to not have to deal with:
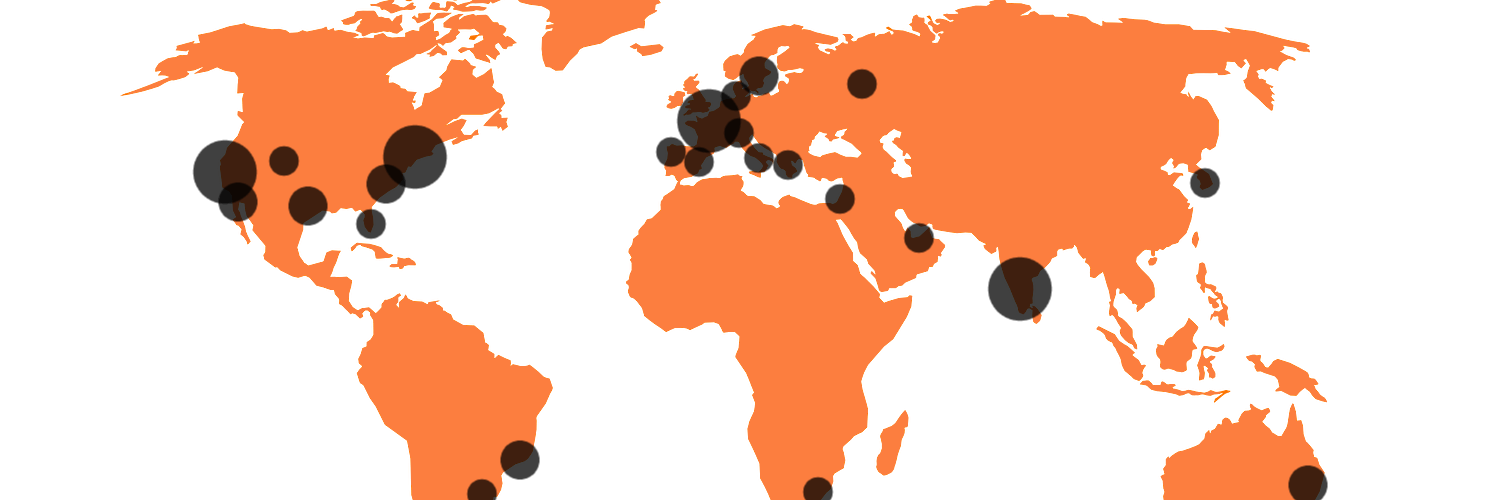
I recently pushed some PHP code to cluster coordinates that helped me cope with hundreds of thousands of geographic locations.
Turns out drawing all of those on a map isn’t that trivial…
Building scalable software means that you are prepared to accommodate growth. There are basically 2 things you need to consider as your data grows:
Obviously, you will need more infrastructure as you grow. You’ll need more machines. You’ll probably also need/want to introduce additional applications to help lighten the load, like cache servers, load balancers, …
A myriad of features may prompt the need to aggregate your data, like showing an average score based on multiple values, or even simply showing the amount of entries that abide to a certain condition. Usually this is a trivial query, but this is often untrue when dealing with a huge dataset.
In content-heavy websites, it becomes increasingly important to provide capable search possibilities to help your users find exactly what they’re looking for. The most obvious solution is searching your MySQL database directly, but implementing a generic MySQL search is not at all trivial. Here’s how to avoid those pitfalls and build a robust MySQL-powered search engine for you website.
This article will solely focus on the most common text-based search (as opposed to e.g. geography- or time-based)